Pack & cap: adaptive DVFS and thread packing under power caps
Ryan Cochran, Can Hankendi, Ayse K. Coskun, Sherief Reda
Reduce the power budget on a running server and performance goes up. That's not a paradox, it's what happens when you stop wasting power on the wrong configuration. The uncomfortable truth is that DVFS alone, the industry default for power-capped systems, leaves enormous efficiency on the table because it ignores a second control knob sitting right there in the OS: which cores the threads actually run on.
We built Pack & Cap to use both knobs together, adapting voltage-frequency settings and thread-core affinities simultaneously at runtime. Here's what we found.
TL;DR
- Thread packing (confining N threads to fewer than N cores, letting idle cores sleep) extends the feasible power-cap range by an average of 21% compared to DVFS alone.
- Pack & Cap reduces workload energy consumption by an average of 51.6% versus existing DVFS-only techniques that achieve the same power range.
- Our runtime classifier meets the power constraint 82% of the time, with no power meter required during online operation.
- The optimal thread count and V-F setting are strongly workload-dependent and shift as the power budget changes. A static policy is almost always wrong.
- We train offline using performance counters, temperatures, and power data, then deploy using only performance counters and thermal sensors, making this genuinely low-cost to deploy.
The Key Insight
Running four threads on four cores at a lower frequency is not the same as running four threads packed onto two cores with the other two sleeping. The second configuration draws less static power from the idle silicon, changes the memory access pattern, and can hit a lower total power draw without sacrificing as much throughput as simply dialing down the clock.
The subtler point: thread packing is dynamically reconfigurable with zero application modification. In Linux, you set thread-core affinities via thread IDs. No recompile, no runtime library, negligible overhead. Thread reduction, the alternative where you actually launch fewer threads, requires touching application code and can't be changed mid-execution gracefully. Packing wins on practicality even before you look at the performance numbers.
The Experimental Story
Before building the controller, we needed to understand whether thread packing and V-F setting choices actually matter, and how much they interact. We profiled all 13 PARSEC benchmarks across 9 voltage-frequency levels and 1, 2, or 4 thread configurations, measuring runtime, power, and energy across the first 100 billion retired micro-ops in the parallel phase.
The first result stopped us: in the unconstrained case, 4 threads always wins on both runtime and energy, regardless of V-F level. That seems obvious for runtime, but energy? We expected some workloads to prefer fewer threads for energy efficiency. They didn't. Four threads on four cores at the right frequency dominates. This tells you that any power-capped strategy that starts by reducing thread count is already fighting against the workload's natural efficiency point.
The energy-runtime tradeoff curves reveal why V-F selection is non-trivial even without thread packing. Canneal's optimal energy point sits at 2.13 GHz, not the highest frequency. Blackscholes hits its energy minimum at 2.53 GHz. These curves are convex-shaped but the minima are workload-specific and non-obvious from first principles.
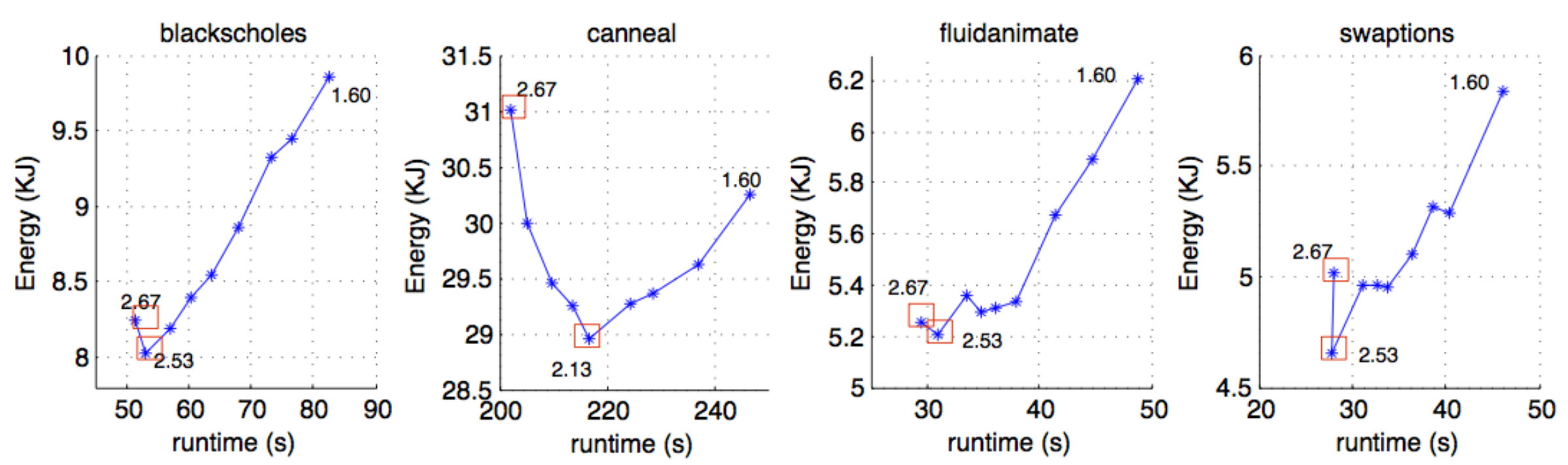
Next we asked: does packing four threads onto fewer cores actually behave differently from just running fewer threads? Across 117 comparison points, thread packing is 2.1% faster than thread reduction on a single core and 1.0% more power-hungry. The gap is small but consistent. More importantly, packing gives you a control knob you can change at runtime. Reduction doesn't.
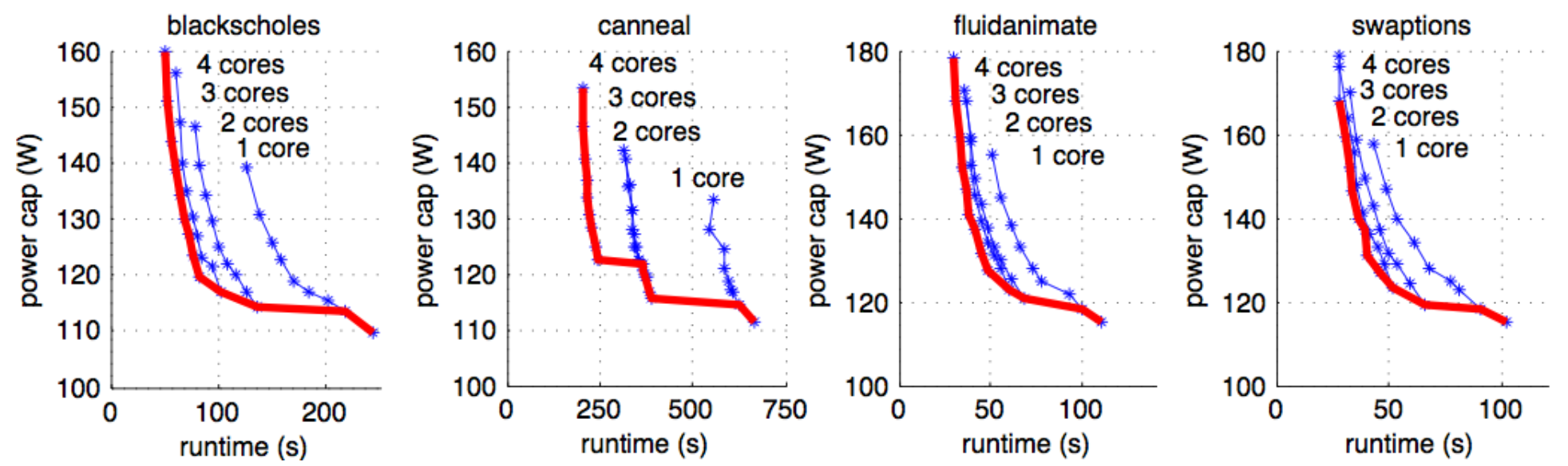
Then we looked at what happens under power caps. We swept power constraints from ~110W to ~180W and plotted runtime against cap for each core-count configuration. The key finding: no single thread count dominates across the full range. At high power budgets, 4 cores wins. As the cap tightens, 2 cores or even 1 core becomes optimal. The efficient frontier across all power levels is a composite curve that requires switching core count as the budget changes. DVFS alone, which assumes all cores stay active, can't reach the lower-power points on this frontier at all.
How It Works
Pack & Cap splits into two phases: offline learning and runtime control.
Offline, we collect performance counter readings, thermal sensor data, and power measurements while running each benchmark across all 27 operating points (9 V-F levels times 3 thread configurations). We compute feature ratios from these readings, forming a feature vector Phi(x), and label each observation with the optimal operating point for a given power constraint. A multinomial logistic regression classifier learns the mapping from features to optimal operating point. We use L1 regularization to find the most predictive subset of features automatically, which keeps the model compact and reduces overfitting. The result is a set of weight vectors, one per power constraint level, stored in lookup tables.
At runtime, the system reads performance counters and thermal sensors (no power meter needed), computes Phi(x), looks up the weight vector for the current power cap, and runs the MLR forward pass to get a probability distribution over operating points. The highest-probability point becomes the new V-F setting and thread-core affinity assignment. The controller then updates both knobs.
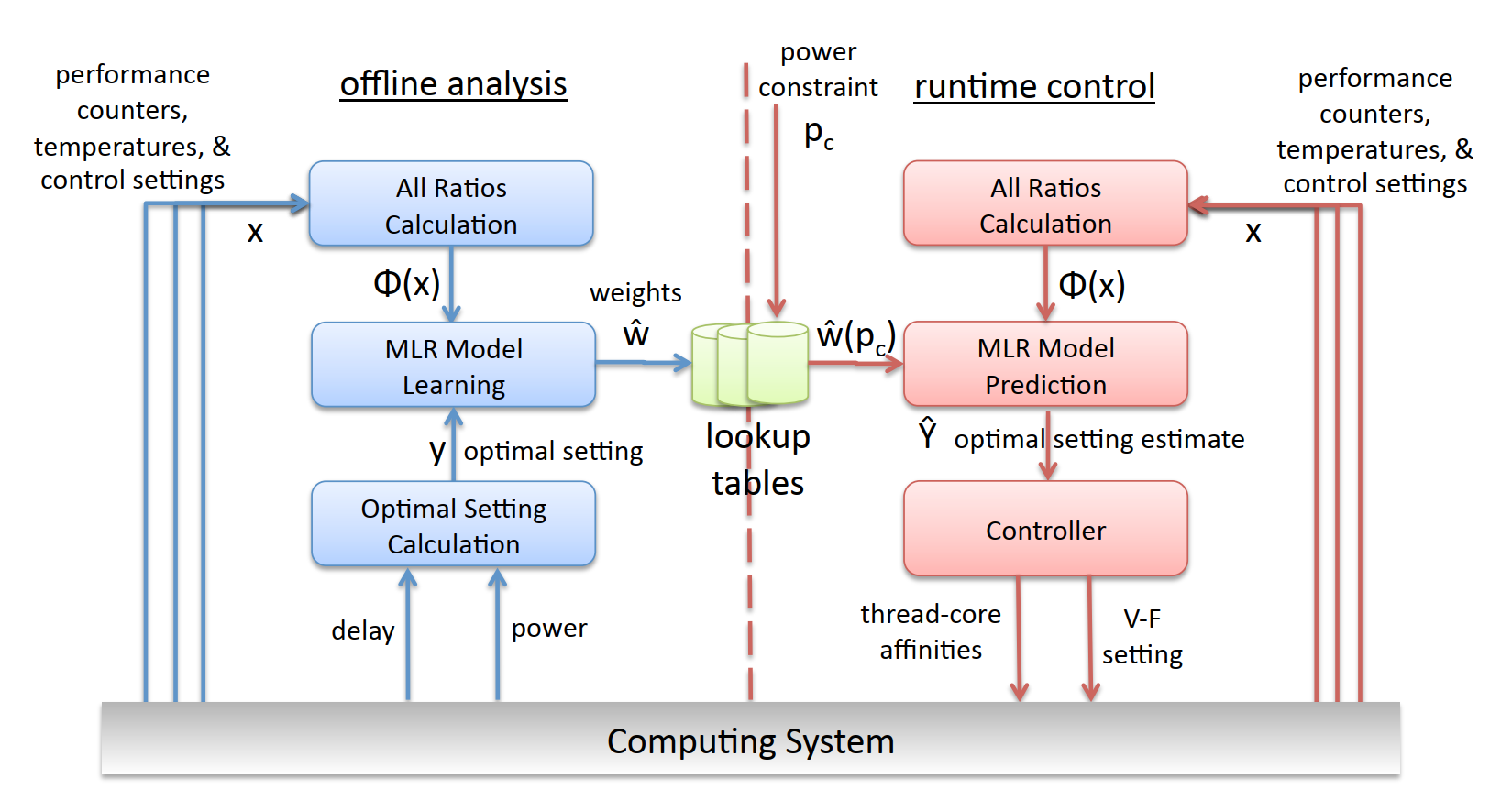
The absence of a runtime power meter is a deliberate design choice, not a limitation. Power meters add hardware cost and latency. Our classifier infers power state from counters and temperatures, which are universally available on modern processors.
Key Results
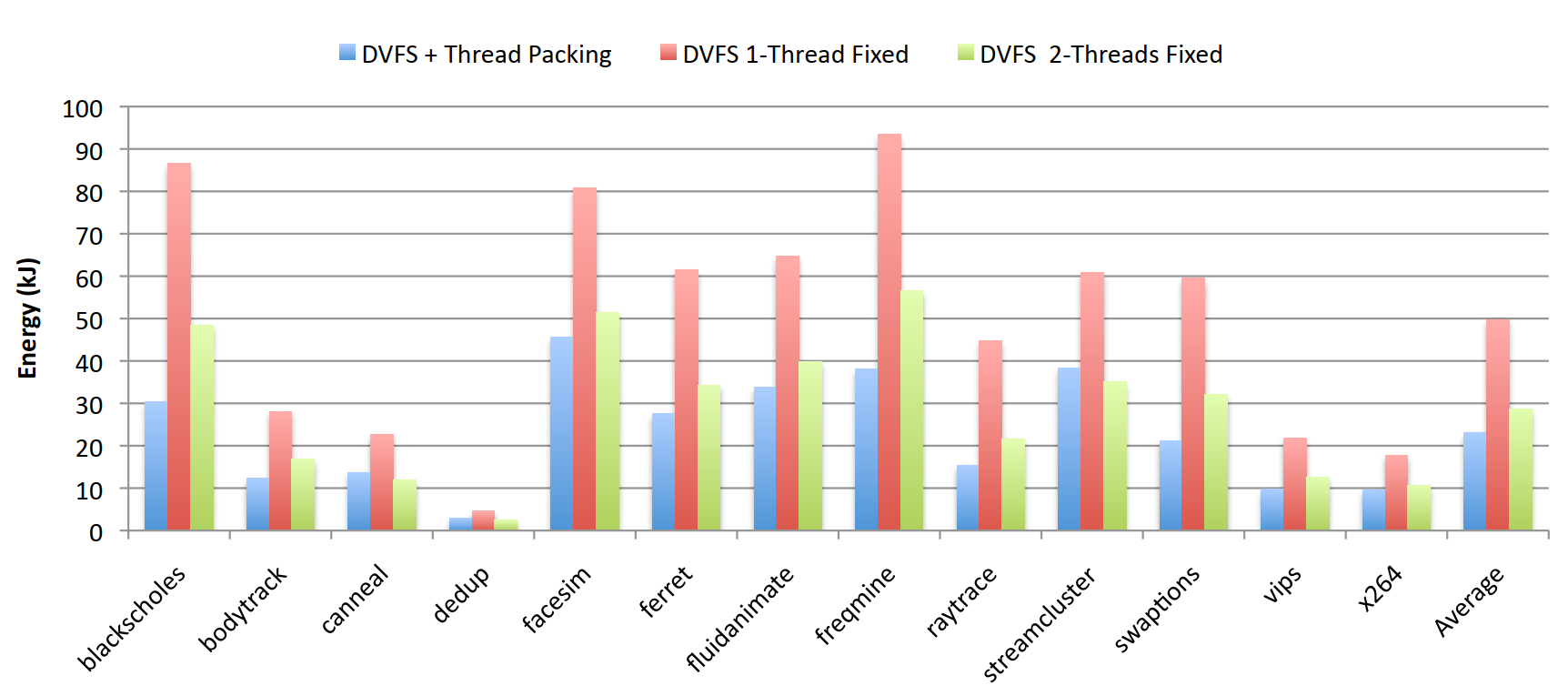
- ✓51.6% average energy reduction versus DVFS-only baselines across all 13 PARSEC benchmarks. The gains are largest for compute-bound workloads like blackscholes and freqmine, where thread packing dramatically lowers idle-core static power.
- ✓21% larger feasible power-cap range with Pack & Cap versus DVFS alone. This means data centers using only DVFS literally cannot honor low power budgets that Pack & Cap handles comfortably.
- ✓82% constraint satisfaction rate at runtime with no power meter. This holds even as we change the power cap dynamically mid-execution.
- ✓DVFS-only Pack & Cap (thread packing disabled) still outperforms prior DVFS techniques in the literature, showing the MLR classifier adds value even without the second control knob.
Takeaways
We're confident that combining thread packing with DVFS is strictly better than DVFS alone for power-capped multi-core systems. The mechanism is clear, the results are consistent across 13 diverse workloads, and the implementation overhead is negligible.
The limits are real. We validated on a single quad-core Intel Core i7. The classifier is trained per-workload offline, so it requires profiling before deployment, which doesn't fit every use case. The 18% of constraint violations matter in applications where hard power guarantees are non-negotiable.
What's still open: we haven't extended this to multi-socket systems, heterogeneous cores, or workloads that dynamically change their parallelism structure. Hyperthreading is disabled in our setup. All of these are tractable extensions with the same MLR framework.
The thing worth remembering: the optimal operating point under a power cap is not a fixed setting, it's a function of the workload's current behavior, the thermal state, and the budget. Any controller that ignores one of those three inputs is leaving performance on the floor. Pack & Cap reads all three.