Identifying the optimal energy-efficient operating points of parallel workloads
Ryan Cochran, Can Hankendi, Ayse Coskun, Sherief Reda
Running parallel workloads efficiently is surprisingly hard. More threads and higher frequencies don't always mean better performance, and they definitely don't mean lower energy. The optimal operating point depends on the workload itself, and picking wrong can cost you 30% or more in energy efficiency.
TL;DR
- 51% higher decision accuracy compared to prior DVFS techniques that rely on memory operation frequency alone
- Optimal operating points are highly workload-dependent: some benchmarks favor low frequency with all threads, others favor high frequency with fewer threads
- L1-regularized multinomial logistic regression automatically identifies the 10 most relevant hardware counters from dozens of candidates
- Achieves 10.6% average EDP improvement across PARSEC benchmarks, with up to 30.9% maximum improvement on individual workloads
- The technique handles multiple optimization objectives (min delay, min energy, EDP, ED²P) with the same framework by simply retraining
- Thread count modulation is a first-class control knob alongside DVFS, not an afterthought
The Core Idea
Think of finding the optimal operating point like tuning a car for a specific race track. A drag strip rewards raw horsepower. A winding mountain road rewards handling and efficiency. You can't know the right setup without understanding the track.
The same applies to parallel workloads. Some are compute-bound and benefit from maximum frequency and thread count. Others hit memory bottlenecks or synchronization overhead that make additional threads counterproductive. The key insight is that hardware performance counters already contain the information needed to predict which "track" you're on. We use multinomial logistic regression with L1 regularization to learn which counters matter and how to map them to optimal settings. The model runs at negligible overhead and makes per-interval predictions about the best thread count and frequency combination.
Why It Matters
Energy consumption in large-scale computing systems grows by over 15% per year. For HPC clusters and datacenters, power management isn't optional. It's a primary factor in provisioning costs and operational expenses.
DVFS is the standard tool here, but it's not enough by itself. Prior techniques mostly look at memory operation frequency to decide when to scale down. That works okay for single-threaded workloads, but parallel workloads are fundamentally different. Thread interactions, synchronization overhead, and resource contention create complex behavior that simple memory-bound heuristics miss entirely. If you're managing parallel workloads with single-threaded techniques, you're leaving significant efficiency on the table.
The other missing piece is thread count itself. Most power management treats the number of active threads as fixed. But for many workloads, running with fewer threads at higher frequency (or vice versa) produces better energy efficiency than any fixed-thread DVFS policy could achieve. We need to optimize both knobs together.
Key Insights from the Experiments
The Optimal Point Varies Dramatically
We collected extensive training data across the PARSEC benchmark suite, measuring power, energy, and performance at every combination of thread count (1, 2, 4) and frequency (1.60 GHz to 2.67 GHz in steps). The results show no single operating point dominates.
For EDP optimization, the distribution of optimal points clusters around lower frequencies with maximum threads: 35% of workload intervals favor 4 threads at 2.00 GHz, another 34% favor 4 threads at 1.60 GHz. But for ED²P optimization, which penalizes delay more heavily, higher frequencies win: 28% favor 4 threads at 2.67 GHz, and 25% favor 4 threads at 2.53 GHz.
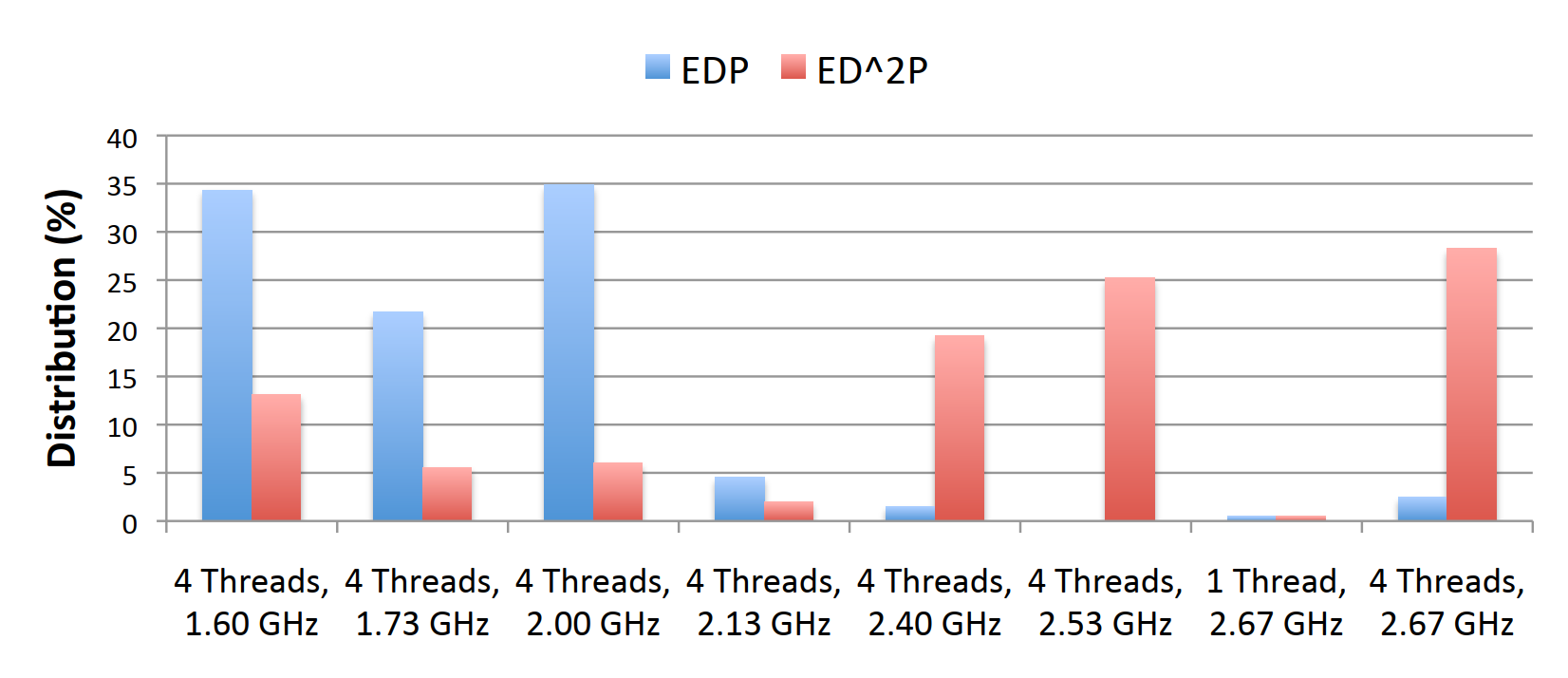
This distribution shift means any static policy is wrong for a significant fraction of workloads. You need dynamic prediction based on actual workload characteristics.
Memory Metrics Aren't Enough
Prior work from Isci et al. and Dhiman et al. used memory operations per micro-op or CPI stack decomposition to guide DVFS decisions. These metrics assume workloads are either compute-bound or memory-bound, and that this distinction tells you everything.
For parallel workloads, it doesn't. Thread synchronization, cache coherence traffic, and resource stalls create behavior that doesn't map cleanly to the compute/memory spectrum. Our L1-regularized model automatically discovered that L2 cache misses, load locks, branch misses, and core temperature are all important predictors, not just memory bandwidth metrics.
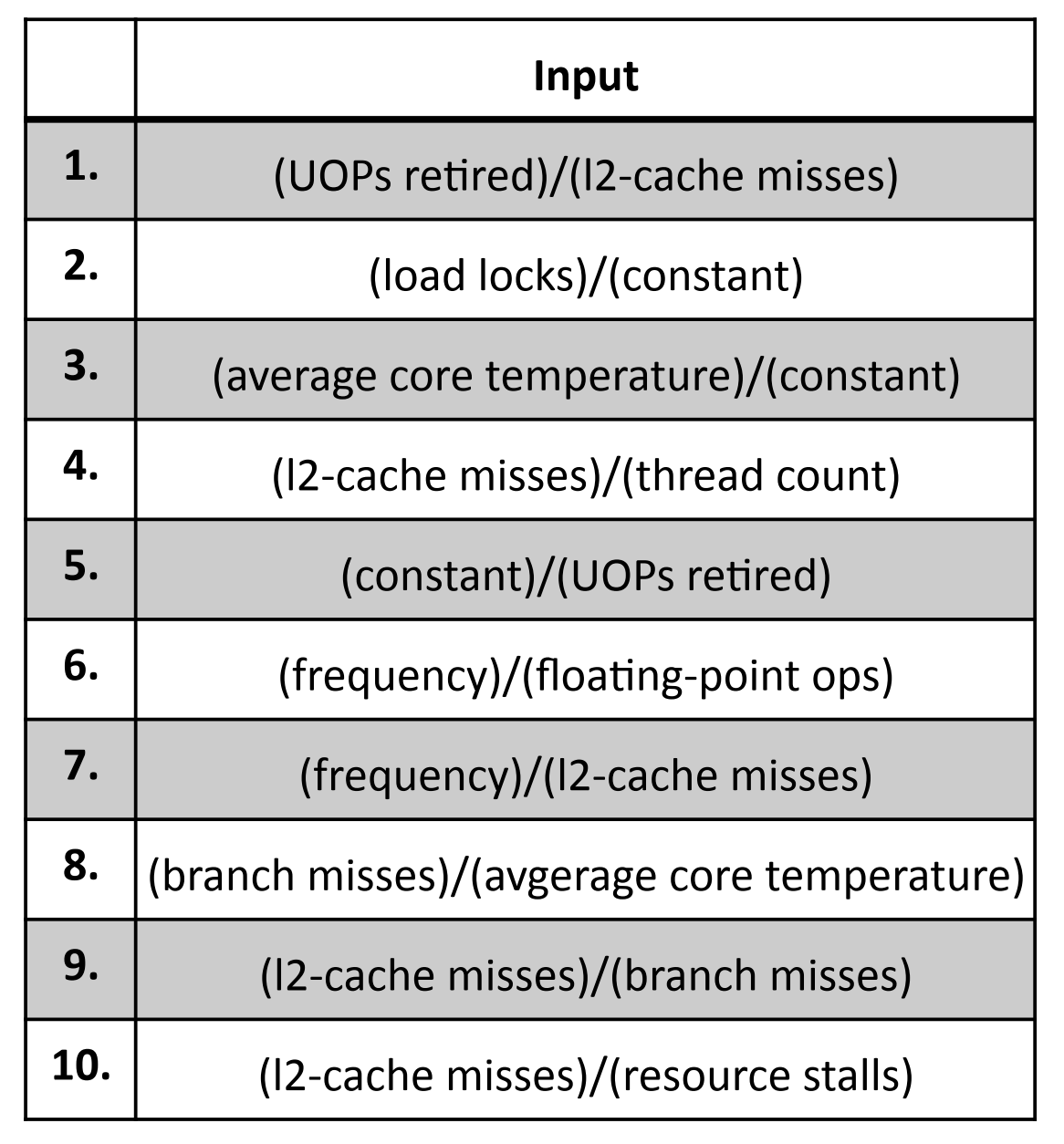
The top feature is UOPs retired divided by L2 cache misses. This captures something like computational intensity, but normalized differently than traditional metrics. Load locks (feature 2) directly measure synchronization overhead. Core temperature (feature 3) reflects power density and utilization patterns. These aren't features you'd pick by hand if you were thinking about single-threaded memory-bound analysis.
Energy Accounting Changes Everything
One of the subtler findings involves what power components you include in the optimization. We measured both processor power (the CPU package itself) and total system power (including motherboard, memory, fans, etc.).
For the blackscholes benchmark, processor energy increases with frequency but decreases with thread count. The optimal point for minimum processor energy is low frequency, high thread count. But total system energy shows the opposite trend because the fixed power draw of motherboard components dominates. When you can't turn off the rest of the system, finishing faster always wins.
We focused on processor energy under the assumption that future systems will have energy-proportional components (low-power memory states, aggressive sleep modes). If your system can actually idle efficiently, optimizing processor energy makes sense. If it can't, you should probably just run flat out and finish as fast as possible.
How It Works
The system operates in two phases: offline training and online prediction.
Offline training collects hardware performance counter data across all PARSEC benchmarks at all operating points. We sample counters every 1 billion micro-ops and measure power using Intel's Running Average Power Limit (RAPL) interface. For each sample, we record the "ground truth" optimal operating point by checking which setting would have produced the best objective value (EDP, ED²P, or constrained variants).
We then train a multinomial logistic regression classifier. The input features are ratios of hardware counters (L2 misses per thread, frequency per floating-point op, etc.). The output is a probability distribution over all possible operating points. L1 regularization forces most feature weights to zero, automatically selecting the ~10 features that actually matter from the initial set of dozens.
Online prediction reads the selected counters at runtime, computes the feature ratios, and evaluates the trained model. The model outputs the probability that each operating point is optimal. We pick the one with highest probability and apply the corresponding thread count and frequency setting.
The key design choice is treating this as classification rather than regression. We don't try to predict energy or delay directly. We predict which discrete operating point wins. This sidesteps the problem of modeling complex nonlinear power/performance relationships. The model only needs to learn decision boundaries, not accurate numerical predictions.
Changing the optimization objective (from EDP to ED²P, or adding constraints) just requires retraining with different ground-truth labels. The feature selection and model structure stay the same.
Key Results
- ✓51% higher decision accuracy than the memory-operations-per-µop approach from Isci et al. Our method correctly predicts the optimal operating point far more often.
- ✓10.6% average EDP reduction across all PARSEC benchmarks compared to prior techniques. This comes purely from making better operating point decisions.
- ✓30.9% maximum EDP improvement on the best-case workload. Some benchmarks benefit enormously from proper thread/frequency tuning.
- ✓Negligible runtime overhead. Reading a handful of counters and evaluating a linear model takes microseconds. The decision interval is billions of micro-ops.
- ✓Superior scalability as operating points increase. Prior techniques that enumerate phases and manually assign policies don't scale well. MLR handles more options naturally.
- ✓Temperature awareness comes for free. Core temperature is one of the selected features, so the model implicitly accounts for thermal behavior without separate thermal management logic.
Takeaways
The main thing that worked well is the combination of L1 regularization with multinomial logistic regression. L1 regularization solved the feature selection problem automatically. We didn't need domain expertise to pick the right counters. The sparsity constraint found them. And MLR gave us a principled probabilistic framework that handles multiple operating points gracefully.
One limitation is that we trained on PARSEC benchmarks. The model captures parallel workload behavior well for scientific and media processing applications, but production datacenter workloads might have different characteristics. The methodology transfers, the specific trained model might not.
Another open question is temporal dynamics. We make independent predictions for each interval, but workload phases have structure. A workload that's memory-bound now is probably memory-bound in 100ms too. Incorporating phase prediction or hysteresis could improve stability and reduce transition overhead.
Looking back, the biggest insight is that thread count deserves equal billing with DVFS as a power management knob. Most systems treat parallelism as an application concern and power management as a system concern. For parallel workloads, those concerns are deeply intertwined. Managing them together unlocks efficiency that neither can achieve alone.